Let’s try doing this the other way around this time. Most of the work from the 0.0.5 milestone is in this image:
Graphic design is my passion
No filler. Let’s break it down.
A renderer from scratch
Up until now, the game used solid quads for the playfield and Dear Imgui windows for everything else. Of course, that wasn’t going to be enough for anything but the most basic test views. The real renderer would have to be able to handle every UI control and all gameplay graphics, run fast, and look beautiful doing it. So, I created a simple 2D software-GPU in compute shaders, which processes parametric 2D shapes instead of triangles.
Yeah. You should be used to my way of solving problems by now.
All shapes you can see above are created with equations, and computed on the fly every frame. There is no rasterization or textures involved, just a whole lot of math. No temporal accumulation is involved either. With this method, perfect analytical antialiasing (equivalent to MSAAx256) is quite literally free, as well as effects like outlines and glows.
Trip through the pipeline
At a high level, the renderer is not too dissimilar from a tiled GPU. The first shaders transform uploaded data from logical space to window space, like a vertex shader; this allows me to use the same coordinate system for any window size and aspect ratio.
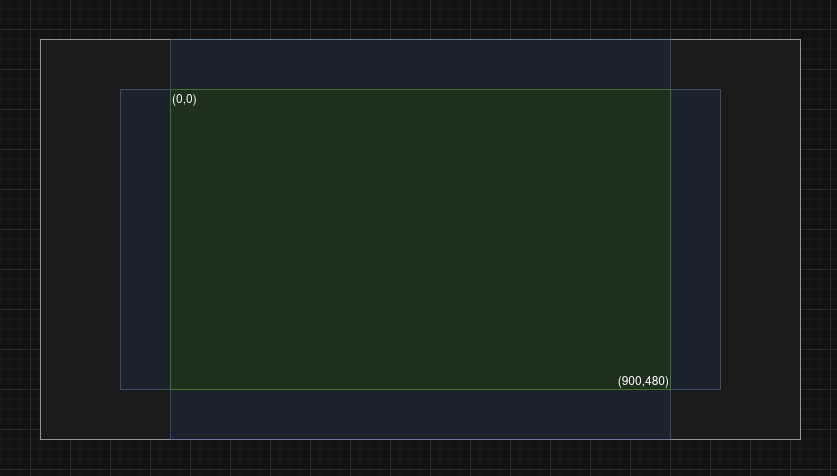
Gray: Screen/window area. Green: the logical coordinate space. Blue: Customizable margin. While the interactive elements are all inside the green area, backgrounds and decorative elements extend outside!
Then, it’s time to assign work. The next shader calculates each shape’s bounding box. Afterwards, the screen is split into 16×16 tiles. Each tile goes through the list of bounding boxes, keeping track of which shapes can possibly be inside it.
Once that’s done, it’s time to draw. Each pixel of the screen finds its tile, reads the list of shapes that tile might contain, and loops through it to draw everything at once. The screen goes from blank to finished here, in this one compute dispatch.
Debug heatmap view of the test scene. The more shapes in a tile, the more it’s tinted red.
Features
Basic shapes: circle, pie slice, rectangle, capsule, line (butt, square and round caps) (yes it’s really called “butt”), polygon, glyph
Funfact: the alpha blending is actually done front-to-back! The usual operator is inverted, compositing a new color behind the ones already blended. The benefit of this approach is that once the pixel is fully opaque, there’s no point in going any further back – the remaining shapes are fully occluded, and won’t provide any contribution to the final color. The blend operator also works in linear space, and uses premultiplied alpha for plausible and pleasing results.
Subpixel rendering (also known as ClearType on Windows) is typically used for text, but this renderer can do it for all graphics! By default it uses the same setting as the OS, but this can be overridden in the config.
These times are in nanoseconds. That means drawing the entire frame containing the test scene above takes 0.16ms.
Other changes
The renderer’s the big thing, but there’s a few other changes that deserve a mention.
Switch to Slang
Playnote’s shading language of choice is now Slang, which has recently been adopted by the Khronos Group of Vulkan fame. It’s still a bit rough around the edges, but is seeing active and rapid development, and is already incredibly powerful and expressive compared to the major players, and I experienced far fewer compiler crashes and miscompiles with it than with dxc‘s SPIR-V output.
To support it, Playnote’s required Vulkan version is now 1.3. This should be fulfilled by every GPU out there still receiving updates.
Low latency mode
In practice, ultra-low audio latency is wasted if the visuals aren’t snappy to match. To improve video latency, Playnote now implements a home-made version of Reflex, waiting until the last possible moment to prepare and present a frame. The difference is quite noticeable – it combines the latency of VSync off with the energy savings of VSync on. It requires a reasonably stable level of performance, and so it can be disabled in the config in case it causes stutters; it replaces the option to disable VSync.
Another new config option changes the number of swapchain images; this is best known as single/double/triple buffering. The smaller the value, the better the video latency at the cost of higher performance requirements. It’s set to double buffering by default as a reasonable middle ground. Some compositors don’t allow setting this below a specific amount; in that case the game will still start, but the setting will be ignored and a warning printed to the logs.
Less system dependencies
This only matters for people building the game from sources, but it should now be a fair bit easier on Linux – nearly all dependencies are built by vcpkg rather than needing to be installed from the system package manager. This also unifies the build system further between the Windows and Linux versions.
Heap management
It turns out that the default implementations of memory allocators like new and malloc() aren’t very efficient, and there are many efforts out there to improve them. Playnote tries to be smart about memory, but still allocates a lot, so a switch to a third-party allocator is as close as you can get to basically free performance. Mimalloc is my allocator of choice for this. As a side effect, on Windows the game will now have to ship with a bunch of .dll files alongside it so that it can properly replace calls to the system allocator.
Asset packing
With font rendering come atlases and .ttf files, both of which need to be loaded by the game at startup. I could load them directly as files, but sqlite is faster than the filesystem, so naturally I did the faster thing. All assets are now packed into a single .db file, and optionally compressed with zstd. It feels cleaner too, I never liked cluttering the install folder.
Wayland support
Wayland support is now enabled in glfw, so Wayland users on Linux will now get a native window. That’s it.
Project news
Due to lack of confidence in GitHub‘s recent direction, Playnote has migrated to Codeberg. The GitHub project is now archived; all further development continues on the Codeberg project. CI builds are temporarily unavailable during migration to a new CI provider.
In case you missed it, Playnote now has a Discord server! Join to discuss development and be notified of new updates and blogposts.
What’s next
The new renderer needs to be put to work! 0.0.6 will involve designing common UI controls out of the available shapes, until the makeshift Imgui views can be entirely replaced. Stay tuned.
A month since the first one! 31 days, on the dot! One of these days I won’t start a progress report shocked about how long it’s been, but not today. It’s been a time of massive redesigns, stability / performance improvements, and creation of the most robust song importer the world of BMS has ever seen. Let’s dive into each change, from the foundational to the flashy.
No images to wetten up the dry text this time, sorry. I’ll make it up to you in the next one. Actually, here’s my cat, why not.
Mood.
Thread rebuild
With the move from mutex-based channels to lock-free queues, every role of the audio thread became redundant, and so it got the axe. There is now only input and render. The input thread, aside from being the initial thread, mostly just spins collecting and sending out user input events. render, on the other hand, handles pretty much everything else – it sets up audio, video, file ops. A lot more threads than that are implicit though, and managed by their respective libraries; the logging library has a backend thread for asynchronous I/O, and audio is generated by running callbacks in the OS-managed realtime thread.
These audio callbacks are where the magic happens. They own a lock-free queue that collects user inputs from the input thread. All audio pushed to the sound device is generated ad-hoc by advancing the playing chart by one sample at a time (typically 1/44100th of a second), giving it any relevant inputs in the process, and receiving back requests to play audio files. The chart itself generates note hit events into its own queue which the render thread handles in its own time, judging the hits and accumulating score without the pressure of having to meet a CPU deadline much tighter than the length of a frame.
To put it more simply, a chart here is essentially a samplerVST. The new architecture skips some of the middleman steps that were previously present, and guarantees even lower latencies and jitter.
Coroutines
Some of the planned features involve code running in the background, plugging away at their job while you play the game. Loading a BMS chart takes longer than a frame, and it would be best if the game didn’t freeze up in the meantime. Some tasks are parallelizable, while others are long-running; some are even both. Playnote needed a centralized solution for this to make sure the OS doesn’t get overwhelmed with a mass of threads if many of these tasks happen to be running at once, which would result in slowdowns and stutters.
Initially, I played around with a hand-written thread pool that takes tasks from a queue, each thread pool worker running its task to completion before taking the next one. This approach had a major fault, which surfaced as soon as tasks started spawning and waiting on other tasks to complete. If there were more jobs waiting for another job’s completion than there were workers, it was possible for all workers to get stuck with them, and there would be no more further progress. A deadlock.
This would be resolved if, instead of waiting around for others, idle workers could pick up one of these jobs they depend on. (If you want something done, do it yourself!) This is exactly what coroutines implement. A coroutine is a function that is able to suspend itself, giving the executor a chance to switch to other work. This operation is called yielding. A special kind of yield is an await, which spawns another coroutine and then yields until it’s complete, returning the result value back to the awaiter; this is coroutines’ replacement for promise/future message passing, and feels just like calling a function, making for more readable code.
The coroutine runtime can be single-threaded, which is most often used to “fill in” the CPU time during long operations, like storage access or network requests. This is what allows JavaScript code on a website to work on multiple tasks concurrently, even though each tab is a single OS thread. A multi-threaded one, a pool of coroutine runners, is best for parallelization of complex work. Coroutines implement a model called cooperative multitasking, where tasks relinquish control voluntarily, as opposed to preemptive multitasking, where a scheduler can switch between threads at any point. Because suspend points are known in advance, the switching operation can be lighter and faster.
It sounds very elegant, but the support for coroutines, added in C++20, provides only the fundamental building blocks. A separate library needs to build on top of them, implementing the executor and other abstractions. I went with libcoro, which is a somewhat arbitrary choice, but it’s working well enough.
Playnote now uses coroutines for every operation that can be expected to take more than one frame. The task pool workers are set to low priority, ensuring they don’t eat into CPU time of the main threads. As a result, the game is silky smooth and responsive even during loadings or background operations.
Chart database
Frankly, providing the chart to play as a command-line argument doesn’t make for the best user experience. To do better than this, information about a chart needs to be saved somewhere, so that it can be recalled in the future. This is also an opportunity to cache the results of some of the more expensive calculations, like volume normalization or generating the note density graph, so that every subsequent loading is much faster.
A database is the perfect tool for the job, and Playnote‘s choice is, unsurprisingly, sqlite. It might be the single most widespread library in the world. It’s insanely fast, and so robust it doesn’t get corrupted even if you pull the power plug mid-transaction. One incredibly overengineered wrapper API later, and we’ve got the charts saving. To uniquely identify a chart, Playnote uses their MD5 checksum. It’s an old algorithm, but one that has been used by BMS internet rankings and difficulty tables since forever, and it’s good enough for this purpose.
Song format
Caching calculations helps a lot, but there’s more that can be done to speed up loadings. Chart metadata is now known in advance, but the audio files still need to be loaded from disk every time. This can be improved by optimizing the way the files are stored.
Videogames routinely pack their assets into proprietary containers, so that reading them is faster than filesystem lookups. Some obfuscate or even encrypt them to prevent reverse-engineering. I decided against this approach for Playnote, though. Many users of BMS already have massive song libraries, and keeping Playnote‘s optimized version around would double the space usage. I wouldn’t expect anyone to delete their original library, since the optimized version would be unusable with any other BMS client, should they choose to go back. Can we get the benefits of an asset pack without “monopolizing” the data?
After much thought, I decided on the following format, which I call the songzip:
BMS files are stored at the top level (not in a subfolder),
All files use the STORE method (uncompressed),
“Wasteful” formats, like WAV or BMP, are re-encoded into OGG Vorbis and PNG, respectively.
Let’s go through these points in order.
A valid zip archive + all filenames use UTF-8
With these requirements met, a songzip is just an archive that can be easily opened and extracted on any computer running any OS. If a user wishes to switch away from Playnote, all they need to do is extract all the songs from their zips into folders, and the resulting library will work with older clients.
BMS files are stored at the top level
This speeds up finding of dependent files (audio, images, etc.) by eliminating any folder structures. On songzip load, an in-memory database of all files inside is created, with an index on the filename column to accelerate lookups. For media files, the extension is removed. If a BMS chart requires foo.wav, a SQL query for a file of type audio called foo finds it rapidly and efficiently.
All files use the STORE method
Decompression is fast, but the decompressed data still needs to be stored in memory. If the files are uncompressed, this can be avoided entirely by memory-mapping the archive. The zip format stores individual files contiguously, so when the files are uncompressed, the complete contents of each file are a single memory section that can be stored as a pointer+size pair into the memory-mapped zone. There are no copies or allocations involved, from start to end. It’s very fast.
“Wasteful” formats are re-encoded
Many BMS songs, especially older ones, use uncompressed media. At the time the compressed formats were still in their infancy, and the CPU requirements for decoding them were not negligible. Later, a WAV version was offered as the “high quality” one while the OGG Vorbis version using very low encoding settings was offered to save space at the cost of audio quality. CPUs are now much faster, and the encoders themselves have improved as well; massive space savings are now possible with no perceivable loss in sound quality.
If WAV audio is found, Playnote re-encodes it on-the-fly to an OGG Vorbis file at the q5 quality level, which is the level at which most people agree Vorbis achieves transparency. Better formats are around, most notably Opus, but they don’t work with older clients, defeating the goal of reverse-compatibility. I suppose this feature also makes Playnote a useful mass-optimizer of BMS libraries.
Song importer
But when and how are these songzips created? With this smooth segway, we’re at the meat of the update. First, though, a note on how various rhythm games handle this.
When you want to add a new song to your BMS client, the process is as follows:
Find the song somewhere, typically either the creator’s website or some sort of song pack,
Unzip the song into your BMS client’s “songs” folder (hoping your archive program doesn’t mangle the CJK filenames),
Start the BMS client (if it’s already open, you have to close it first),
Push the button to refresh the song database,
Go have a cup of your hot beverage of choice,
Once it looks like the window finally unfroze, check if the song was actually added.
On the other hand, this is the process of adding a new song in osu!:
Find the song on the game’s website or the in-game downloader,
Click it or drag the file onto the game window,
Wait up to a few seconds for the song to be imported and available.
It’s no surprise which one of the two has a larger player base.
There is no technical reason why BMS can’t be as friendly to use. The format’s various historical warts provide some extra engineering challenges, but solving them should be the job of the programmer rather an extra burden on the user.
The process of adding a new song in Playnote is currently this:
Find the song somewhere, typically either the creator’s website or some sort of song pack,
Drag the archive (or the folder where you unpacked it) onto the game window,
Wait until it’s finished, or play the game in the meantime.
Here’s what it looks like in practice:
It has been implied throughout this post, but Playnote does its best to maintain the grouping of charts into songs. In a vacuum there is nothing connecting all the charts of the same song; any metadata field can, and often is, different between each of them. They are only connected by the fact that they are in the same folder, and require most of the same files to play. By reflecting this relationship in the database, it will be possible to implement a better search, better navigation, and features such as 2-player battle with each player on a different difficulty of the same song.
But I digress. The chart importer takes as its input a list of files dropped into the game window, and its ultimate purpose is to create songzips from any BMS songs detected within the list and then import any charts inside into the database; ideally with as much parallelization as possible. I’ll go in more detail through all the steps it takes in order.
Locating sources
The user might want to import a single song, a song pack, or their entire BMS library. Any of the songs might be an archive, or a directory. To handle all of these possibilities, these scenarios are expected:
The import location is an archive,
The import location is a song directory,
The import location is a folder structure containing song archives or directories.
The last point is handled by recursive traversal; if the dropped path is a directory, and it doesn’t directly contain any files with a known BMS extension, an import task is spawned for every directory inside it.
Preparing the source
Once we have either an archive or a folder directly containing BMS files, this path is used to construct a source abstraction. From this point on, both directories and archives are iterated with the same syntax, so the rest of the importer doesn’t have to care about the distinction.
In the archive case, a little more work needs to be done behind the scenes. To avoid issues with filename encodings, the list of all filenames in the archive is fed through a heuristic encoding detector (the same one used for the contents of BMS files themselves). Archives can also have subdirectories, so the prefix is detected – the shortest path that needs to be taken to reach a BMS file.
Creating the songzip
With the source abstraction in place, the songzip can be created. The archive is created in the game’s “library” folder, with the same filename as the original folder / archive (with a number appended if that’s already taken). As the files are processed, format conversion is performed as needed. Once finished, it’s time to create the in-memory database that serves as a file registry for fast lookup that follows the BMS rules of case-insensitivity and ignoring the extension.
Complication: What about duplicates?
Automatically maintaining a connection between charts of the same song comes with many benefits, but adds complexity as well. What if the player is importing a song that’s already in the library? The MD5s will be duplicates, but we don’t know that we shouldn’t create a new songzip yet. To resolve this, the charts are checksummed and checked against the database directly from the source. If even one of these checksums already exist in the database, the entire song is assumed to be a duplicate. The songzip is still created, but by extending the existing file with whatever contents it’s missing, in case the new import is a superset of the existing one. This is how a user is able to add extra difficulties, known as “sabuns”.
Spawning chart imports
The songzip is created and ready for use, so now we can enumerate charts and import each one. As part of the import process they will need to render out their audio, and for that they will need the song’s audio files. Most of the charts will need the exact same files, so to avoid redundant work, the songzip allows for an optional preload step. The audio files are loaded and decoded from their original audio format to raw samples, and stored in a cache. Later, if a chart loads a file but it already exists in the cache, the cached version is served.
Chart imports
This is the part where metrics, statistics and other expensive one-time operations are precalculated so that they can be cached in the database. All logs from this part of the import process are captured and saved in the database as well. In the future these import logs will be available for reference, in case the chart doesn’t seem to be playing correctly and the user wants to know if it’s because Playnote didn’t like something in the BMS file.
The preview audio is generated in this phase as well, a 15-second snipped from 20 seconds into the song. This will be encoded as a 64 kbps Opus file, and saved into the database. Previews are generated per-chart rather than per-song, because different charts of the same song do sometimes have slightly (or majorly!) different audio.
Finalization
Once all chart imports are complete, we’re just about done. If none of the charts were actually successful, there’s no point in keeping the songzip around, so it is deleted from both the database and the “library” folder. Otherwise, an additional preview deduplication step is done, saving space by pointing all charts whose previews are nearly identical at the same preview file via a many-to-one relationship in the database.
Parallelism
We’re still not done! While each song does follow the process outlined above, there’s more things to mind once we allow multiple songs and charts to be importing at the same time. While sqlite is thread-safe by default on the statement level, the individual statements from different threads might interleave, which might prove catastrophic if any of them are currently performing atomic transactions. A mutex must be used to make sure that only one transaction is being prepared at the same time.
Error handling
The import can fail at any point, both during song processing and chart processing. Any failure is a thrown exception that is cleanly caught and reported in the logs, without affecting other charts of the song or the rest of the import. Thanks to duplicate handling, you can retry a failed import anytime in the future by dragging the song over again.
Complication complication: No ethical duplication under paralellism
There’s still one big edge case to handle. Duplicates are handled correctly if the song existed before this import job, but what if two of the same song are being imported at the same time? If the timing lines up just right, the two imports of the same song might run in parallel. They will both miss each other’s existence and happily continue, thinking they are the first one.
Resolving this requires that the tasks are aware of what the other tasks are planning to do, but haven’t done yet. To achieve this, a mutex-protected staging area must be consistently used, augmenting the entire import process outlined earlier.
When enumerating the BMS files in the source, the MD5s are checked against the staging area. If any of them exist there, the import knows that it’s a duplicate of a still-ongoing import. It assumes the same song ID as the other import and waits for the ID to become available via a per-ID mutex. If the MD5s aren’t present, the import assumes it’s the first to handle this song, registers its charts with the staging area, and grabs the song ID mutex so that any duplicates that come after are able to wait for its completion.
Lead-out
This milestone alone felt like a whole journey of its own, full of surprise discoveries, unexpected challenges, and unusual destinations – many of the solutions I arrived at were quite different from what I thought they would be. But this is now done and we’re at 0.0.4, with the importer in particular being pretty much ready for the big one-point-zero release someday in the future.
If you’re interested in giving the game a try in its current WIP state, head to the repository to build it, or grab the Windows CI build. Here is how you can find some BMS songs to play, for the time being!
The next milestone, 0.0.5, will replace the current temporary renderer with the proper one that will be used for all game graphics. Stay tuned.
Whew, has it really been half a year? Back then I didn’t expect I would still be working on it after all this time, let alone see it become a Serious Project. But, I’m getting ahead of myself. This is the first Progress Report, so proper introductions are in order.
The story so far
Skip this section if you’re familiar with BMS. If you’re not – it’s a rhythm game that looks roughly like this:
DP BMS gameplay in beatoraja, by yours truly
Rectangles are falling, hit the lane’s assigned key to play the missing sounds in the music and complete the song. The gameplay is the same as beatmania IIDX, a commercial arcade rhythm game by Konami’s Bemani division; BMS is the fan-made version, with all music and charts made by members of the community (yes, all the music is original!) The video shows the 14-key mode (Double Play), my personal preference, but 7-key and others are available as well and are arguably far more popular.
Many clients were made that all play charts in the BMS format, but probably the most legendary of them all was Lunatic Rave 2 by lavalse. It was built largely to resemble and replicate the functionality of the PS2 releases of IIDX, and enjoyed great popularity due to its level of polish and performance. During its time, the BMS community grew by orders of magnitude. Sadly, the game’s development was cut short in 2010, allegedly due the developer losing access to the source code. By 2015, the official website went offline. Projects exist to add features and fix bugs in the most recent version, but since all they have is a compiled executable, it takes painstaking decompilation effort and making larger changes is difficult.
LR2 song select, in all its 640×480 glory
LR2 was followed up by beatoraja, a next-gen BMS client by exch. Written in Java and hosted on GitHub, it expands on LR2’s feature set, adding higher resolutions, more QoL and better stability. While still clunky in some aspects, it’s an incredibly impressive effort, and the best we have right now. The language barrier proved to make it difficult to contribute improvements to the original repository, so western development has continued in forks like Endless Dream.
Motivation
One fine afternoon, I was setting up beatoraja on a new Linux install. Right away, it took half an hour just to get it to start, since I didn’t have Java installed, let alone the required JavaFX library runtime. Importing my massive BMS library took hours, and then… none of the songs were actually imported. The game didn’t tell me why. All I could do was split the library into multiple groups, then try importing each one. Most of them worked, a few didn’t. A few more bisects later, and I identified the three songs that broke the import process if they were present. It was already evening, and I didn’t get to play that day. The next day, I discovered that the game has more latency on Linux, due to the bindings of PortAudio it was using. It also dropped inputs when both Shifts were pressed on the keyboard at the same time, which is apparently an inherent limitation of LWJGL.
I walked away from this experience feeling that we deserve better than this. LR2 is great but dead and buried, and beatoraja is opensource but held back by the choice of programming language and its own architecture. If I wanted my perfect BMS client, I was going to have to do it myself.
6.8 million tiny files, 27 gigabytes’ worth of sector padding
I spent the next few months toying with the idea. Why do we need to store each song as folders of 2000 files that waste disk space and take ages to copy, even on an SSD? Why does updating the library mean I don’t get to play until it’s finished? Why does the game only feel responsive at ~500fps, even though my screen is 144 Hz? Why can’t I play against a friend locally with each of us picking a different difficulty of the same song? None of these problems are inherent limitations of the BMS format, they just need someone to go out there and solve them. I’ve already been walking around with half-designed solutions in my head, and I was confident I’d be able to do it if I put my mind to it.
Finally, the time was right. I lost my job, and needed something to pass the time while waiting for a new one to come along. I pushed the initial commit, and Playnote was born. Soon after, my favorite C++ IDE became free for non-commercial use, further bolstering my motivation. I decided on a goal of making at least one commit per day, no matter how small, which was a great idea in retrospect – it’s really satisfying to watch that daily streak number go up.
Progress
Fast-forward to the present – what do we have so far? Well, the game looks like this:
Don’t judge, the graphics are temporary
It’s being developed in C++23 for Windows and Linux, with a custom audio engine and Vulkan for graphics. Currently, it can load one BMS chart at a time via the command line, and allows you to play it yourself (with a keyboard or a controller) or watch a perfect autoplay. Most charts work, though there are edge cases, and a few uncommon BMS features, like mines and control flow, aren’t yet supported.
The interesting parts, and the most difficult ones, are under the hood. The total input-to-keysound latency is 6ms on Linux and 8ms on Windows (2 or 3ms of audio buffer, +1ms limiter look-ahead, times two for round-trip latency.) The game is heavily threaded, inputs always polled at the highest possible rate, and engine ticks completely independent from the renderer. And it loads songs directly from archives!
There are a few smaller things it already does that no other BMS client has done so far:
A heuristic detects the BMS file’s text encoding, fixing mojibake in both Japanese (Shift-JIS) and Korean (EUC-KR) charts with no need to mess with system locale.
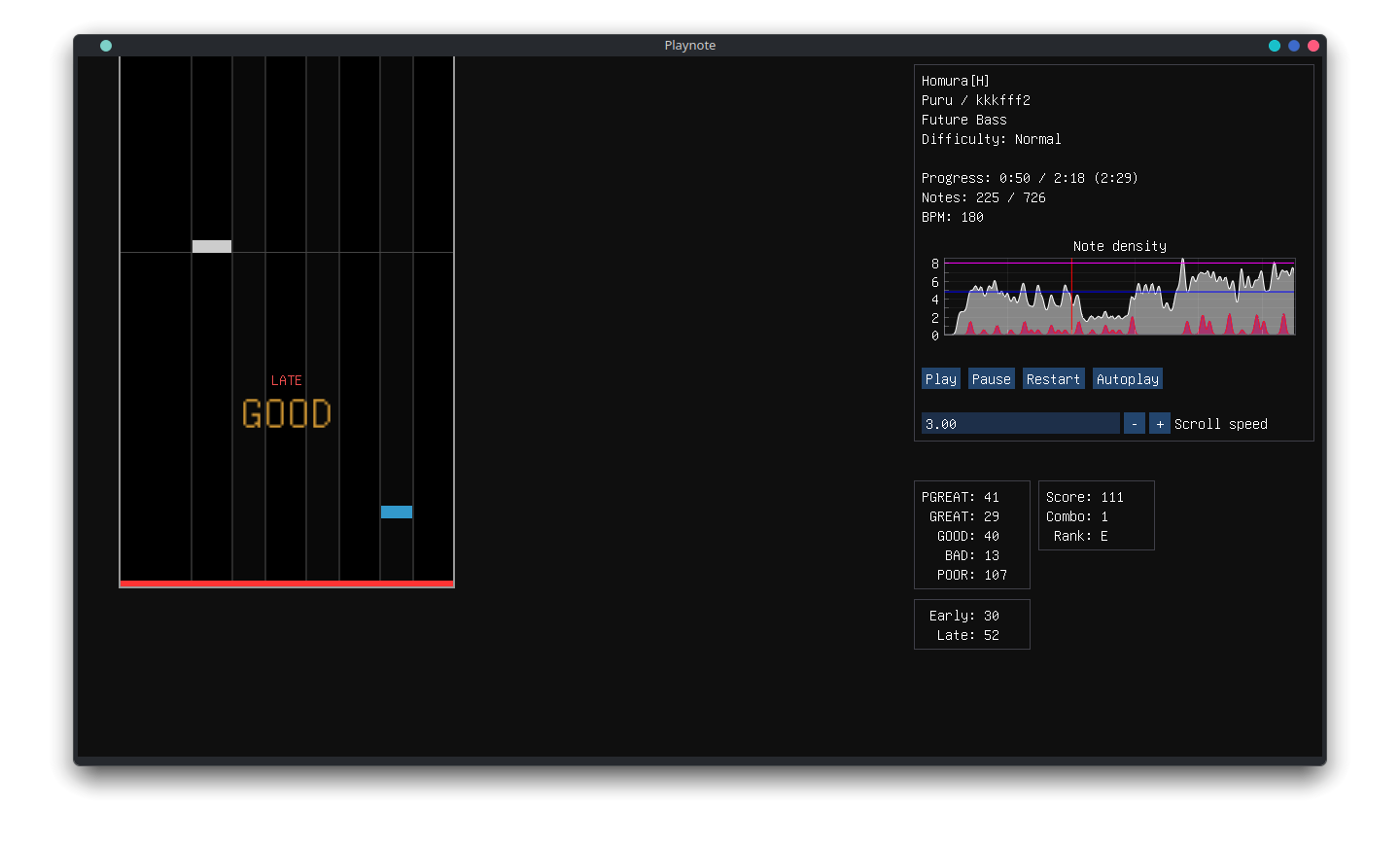
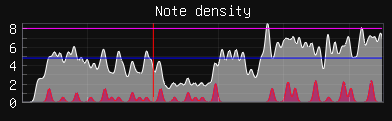
Note density graph is a sum of Gaussians, and the average notes-per-second value uses a root-mean-square based algorithm to be a more useful measure of overall chart density than an arithmetic mean of time-bins.
Blue line shows average NPS, purple shows peak NPS
The future
The next milestone, version 0.0.4, focuses on the chart database and song import process. In other words, it’ll be the first version that’s usable without messing with the command line.
Stay tuned for the next Progress Report! Between them, I might also post some deep-dives into the design process, and stories from development.
If you are interested in giving Playnote a try, you can find the repository here, and the automated Windows build is available in the latest GitHub Actions artifact.